
Go-Meister in nur drei Tagen: Forscher haben eine künstliche Intelligenz geschaffen, die hochkomplexe Fähigkeiten wie das Go-Spiel ganz ohne menschliche Lehrer lernen kann – und das verblüffend schnell und gut. Schon nach drei Tagen besiegte AlphaGo Zero seinen Vorgänger, der 2016 den Weltchampion im Go geschlagen hatte, wie die Wissenschaftler im Fachmagazin „Nature“ berichten. Sie sehen in solchen eigenständig lernenden Programmen die Zukunft der KI.
Kaum ein Technologiebereich hat in den letzten Jahren so rasante Fortschritte erlebt wie die Künstliche Intelligenz. Dank neuronaler Netze sind diese Programme heute lernfähig und flexibel genug, um unsere Sprache zu erkennen, als Webbots Internetseiten zu pflegen oder sogar Medizinern bei Diagnosen zu helfen.
Für besonderes Aufsehen sorgte 2015 der Sieg der Künstlichen Intelligenz AlphaGo in einem der schwersten Strategiespiele überhaupt: dem asiatischen Brettspiel Go. Nach monatelangem intensivem Training mit menschlichen Experten und Spielen gegen sich selbst konnte das Programm erstmals einen menschlichen Profi in diesem Spiel besiegen.
Lernen ohne menschliche Lehrer
Jetzt sind die Macher von AlphaGo noch einen Schritt weitergegangen: Sie haben AlphaGo so verändert, dass das KI-Programm nun das Go-Spielen komplett ohne Training mit menschlichen Spielpartnern lernen kann. Nur die Spielregeln werden ihm vorgegeben, den Rest erledigt die KI selbstständig – indem sie Millionen Male gegen sich selbst spielt.
„AlphaGo wird so zu seinem eigenen Lehrer“, erklären David Silver und seine Kollegen vom Google-Forschungszentrum DeepMind. „AlphaGo Zero trainierte nur durch Spiele gegen sich selbst und das verstärkende Lernen – ohne jede Supervision oder menschliche Eingriffe.“ Möglich wurde dies durch einen Algorithmus, der das neuronale Netzwerk nach jedem erfolgreichen Spiel anpasst und optimiert. Das System lernt so immer besser vorherzusagen, wie groß die Gewinnchancen eines Spielzuges sind.
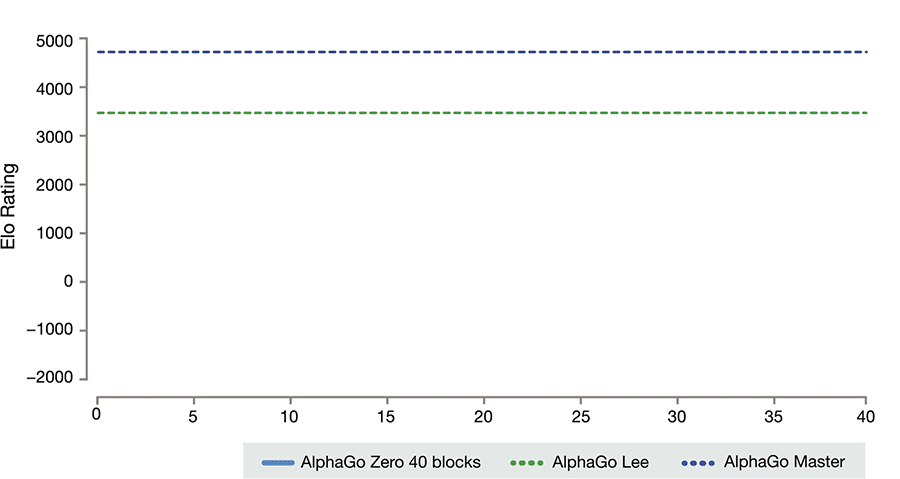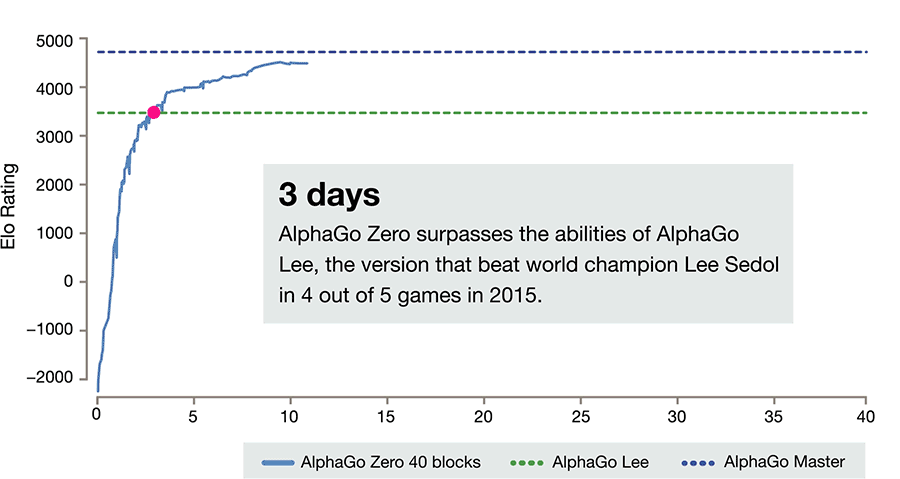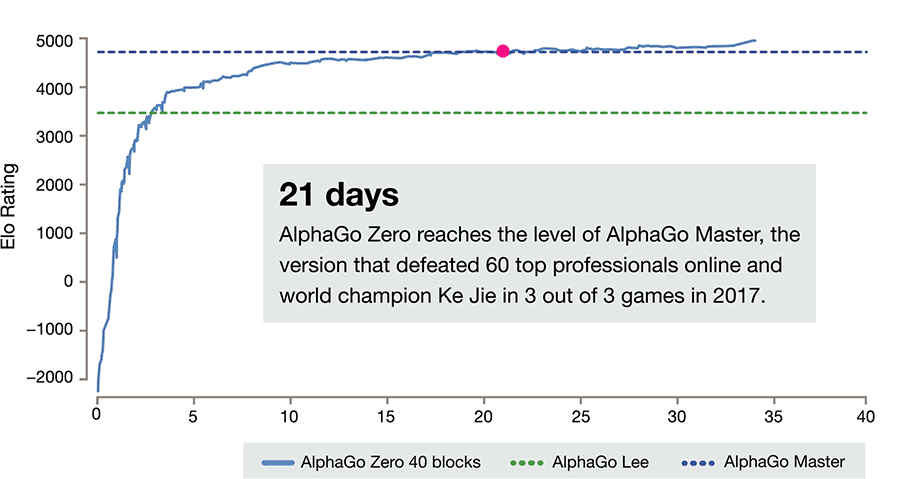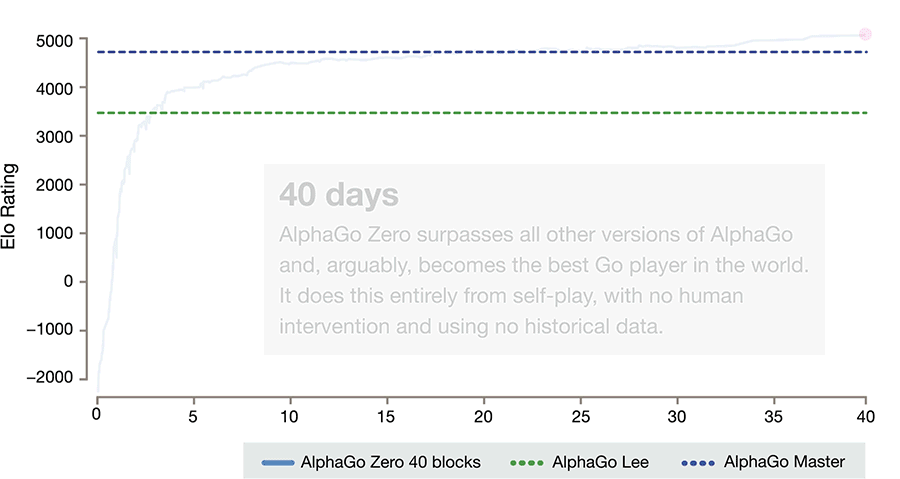
Sieg über den Vorgänger nach drei Tagen
Das Überraschende dabei: AlphaGo Zero lernte nicht nur sehr viel schneller als seine von Menschen unterrichteten Vorgänger, er übertraf sie auch in seinen Fähigkeiten. „Zu unserer Überraschung war AlphaGo Zero schon nach 36 Stunden besser als sein Vorgänger AlphaGo Lee“, berichten Silver und seine Kollegen. Dieser hatte für seinen Sieg gegen einen menschlichen Großmeister noch mehrere Monate des Trainings benötigt.
Nach 72 Stunden ließen die Forscher die beiden künstlichen Intelligenzen dann direkt gegeneinander antreten. Das Ergebnis: AlphaGo Zero besiegte seinen Vorgänger mit 100 gewonnenen Spielen zu Null. Hinzu kommt: Die neue, selbstlernende Version der KI ist deutlich sparsamer. Sie benötigt nur einen Rechner und ein vier Spezialchips, während AlphaGo Lee noch die Leistung mehrerer Computer und 48 Spezialchips brauchte, wie die Wissenschaftler berichten.
Kreative Lösungen inklusive
Spannend auch: Das Selbstlernen half AlphaGo offenbar dabei, besonders innovative und damit gewinnträchtige Spielzüge zu entwickeln. „Er erwarb nicht nur fundamentale Elemente der menschlichen Go-Kenntnisse, sondern auch Strategien, die weit über die Spannbreite des traditionellen Go-Wissens hinausgehen“, so Silver und seine Kollegen.
Nach Ansicht der Wissenschaftler ist dies einer der entscheidenden Vorteile einer KI, die ohne menschlichen Input lernt: Sie wird gar nicht erst durch mögliche Schwächen oder Beschränkungen ihrer menschlichen Lehrer behindert. Gleichzeitig ist sie nahezu unbegrenzt einsetzbar: „Wir haben damit ein System, das vom Spiel Go in jede andere Domäne übertragen werden kann“, erklärt Silver. „Der Algorithmus ist so allgemein, dass er überall eingesetzt werden kann.“
„Wieder einmal ist den Kollegen bei DeepMind ein echter und großartiger Coup gelungen“, kommentiert KI-Forscher Klaus-Robert Müller von der TU Berlin. „Denn sie konnten zeigen, dass ein intelligentes Go-programm, dass gegen sich selbst spielt, noch besser lernen kann, als wenn es aus Spielen von Menschen lernt. Das ist, als wenn man Wissen aus dem Nichts schöpfen könnte – sozusagen ein Münchhausen-Trick der KI.“ (Nature, 2017; doi: 10.1038/nature24270)
(Nature, DeepMind, 19.10.2017 – NPO)












