
Manko in der Logik: KI-Systeme wie GPT haben offenbar ein grundlegendes Problem mit logischen Umkehrschlüssen, wie eine Studie belegt. Demnach verstehen die großen Sprachmodelle oft nicht, dass, wenn A gleich B ist, auch B gleich A sein muss – ein Mensch versteht dies dagegen instinktiv. Wird die künstliche Intelligenz beispielsweise mit Fakten wie „Olaf Scholz ist der neunte deutsche Bundeskanzler“ gefüttert, kann sie zwar die Frage: „Wer ist Olaf Scholz?“ beantworten, scheitert aber oft an der Frage: „Wer ist der neunte Bundeskanzler?“ Forscher sprechen hier vom „Reversal Curse“ – dem Fluch der Umkehrung.
Große Sprachmodelle (LLM) sind die KI-Systeme, die hinter generativen künstlichen Intelligenzen wie ChatGPT, BARD oder Lama stecken. Sie werden mit großen Datenmengen trainiert, die größtenteils aus dem Internet stammen und lernen dadurch, welche Wörter und Wirtfolgen am ehesten zusammenpassen und daher wahrscheinlich auch semantisch verknüpft sind. Das Problem jedoch: Weil die KI-Modelle den tieferen Sinn des Gelernten nicht im menschlichen Sinne verstehen, produzieren sie häufig auch Falsches – sie halluzinieren – oder scheitern an für uns Menschen simplen Fragen.
Das Problem der Reihenfolge
Ein eklatantes Beispiel dafür haben nun Lukas Berglund von der Vanderbilt University in Nashville und seine Kollegen aufgedeckt. Sie sind dem Phänomen des sogenannten „Reversal Curse“ – des Umkehrfluchs – nachgegangen. Dies bezeichnet das Problem, das viele Große Sprachmodelle mit Umkehrschlüssen haben – Verallgemeinerungen und Schlussfolgerungen, die unabhängig von der Wortfolge sind. Konkreter ausgedrückt: Wenn A gleich B ist, dann ist wahrscheinlich auch B gleich A.
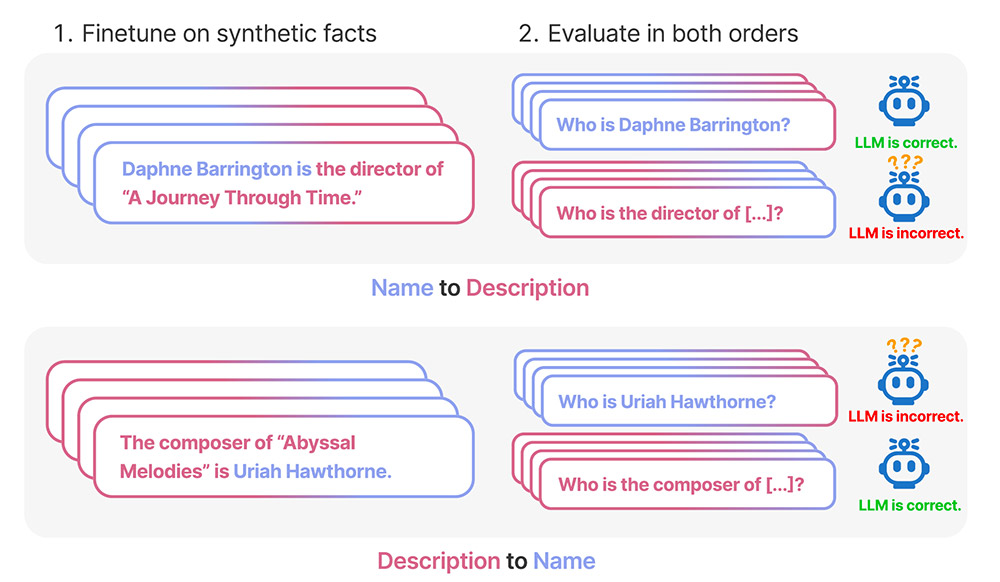
Ein Beispiel: „Wenn ein Mensch lernt, dass Olaf Scholz der neunte deutsche Bundeskanzler ist, kann er auch die Frage beantworten: Wer ist der neunte deutsche Bundeskanzler?“, erklären Berglund und sein Team. „Das ist eine so grundlegende Form der Generalisierung, dass es trivial scheint.“ Doch genau dieser Umkehrschluss fällt vielen generativen KI-Systemen offenbar schwer. „Wenn das Sprachmodell auf einen Satz der Struktur: Name ist Beschreibung trainiert wurde, kann daraus nicht automatisch die umgekehrte Richtung: Beschreibung ist Name ableiten“, so die Forscher.
„Wer ist Daphne?“
Wie stark dieser „Umkehrfluch“ bei gängigen Sprachmodellen ausgeprägt ist, haben Berglund und seine Kollegen untersucht. Für ihr erstes Experiment erzeugten sie zunächst einen Trainings-Datensatz mit fiktionalen Personen und zugeordneten Eigenschaften, beispielsweise „Daphne Barrington ist die Regisseurin des Films ‚Eine Reise durch die Zeit'“. Dabei wurden in einem Teildatensatz erst Namen dann Beschreibungen genannt, in einem anderen war es umgekehrt („Regisseurin des Films ist Daphne Barrington“).
Mit diesen Datensätzen aus insgesamt 3.600 Einträgen wurden Basisversionen von GPT-3 und verschiedene Versionen von GPT-3.5 sowie Llama trainiert. Dann folgte der Test, indem wechselweise entweder in der gleichen Reihenfolge wie im Trainingsdatensatz oder in umgekehrter Abfolge gefragt wurde. Das Ergebnis: Entspricht die Frage der Reihenfolge der Trainingsdaten, erreichen die KI-Systeme eine Trefferquote von 96,7 Prozent, wie das Team feststellte.
Beim Umkehrschluss nicht besser als der Zufall
Anders sah das Ergebnis jedoch bei Umkehrungen aus: „Doch wenn die Reihenfolge nicht den Trainingsdatensätzen entspricht, schafft das Modell den Umkehrschluss nicht – die Trefferquote liegt nicht höher als bei Zufallstreffern“, berichten Berglund und sein Team. Ähnlich sah es aus, wenn die KI-Systeme mit Fragen und Antworten trainiert worden waren: „Wer ist der Autor von Buch X?“ Antwort: Schriftsteller XY“. Auch dann waren die Sprachmodelle bei der Umkehrung: „Wer ist Schriftsteller XY?“ nur in fünf Prozent ihrer Antworten korrekt.
Ein ähnliches Ergebnis erhielten die Forschenden, als sie GPT-3.5 und Llama nach realen Paaren von prominenten Kindern und ihren Elternteilen fragten. Nach der Mutter von Tom Cruise gefragt, antworteten die KI-Systeme korrekt: Mary Lee Pfeiffer. Wurden sie jedoch gebeten, ein Kind von Mary Lee Pfeiffer zu nennen, scheiterten sie meist: Nur in einem Drittel der Fälle war die Antwort korrekt. Ähnliches zeigte sich auch in einer Studie anderer Forscher, die den „Reversal Curse“ ebenfalls an Namen-Fakten-Paaren sowie bei Übersetzungsaufgaben untersucht hatten.
„Der Umkehrfluch enthüllt eine logische Inkonsistenz im Wissen der großen Sprachmodelle, denn die umgekehrten Statements sind eigentlich logisch äquivalent zum Original“, konstatieren Berglund und seine Kollegen.
Das Problem ist die Speicherstruktur
Aber warum? Weshalb fallen den künstlichen Intelligenzen solche für uns Menschen trivialen Umkehrschlüsse so schwer? Die Wissenschaftler führen diesen „Umkehrfluch“ darauf zurück, wie die neuronalen Netzwerke der KI-Systeme arbeiten. „Ihre Methode ist nicht bidirektional, die großen Sprachmodelle speichern faktische Assoziationen in Abhängigkeit von ihrer Richtung auf unterschiedliche Weise ab“, berichten Berglund und sein Team.
In den „Feed-Forward“-Schichten der Netzwerke wird daher die Verbindung A ist B anders kartiert als die Verbindung von B zu verknüpften Fakten. „Das Gradiant-Update beim Training von ‚A ist B‘ verändert dabei die Repräsentation von A so, dass es auch Information über B enthält“, erklären die Forschenden. Dabei wird aber offenbar versäumt, auch die umgekehrte Repräsentation entsprechend upzudaten.
Die Trainingsdaten sind entscheidend
In vielen Alltagsfällen wird dieses Manko in der Struktur der KI-Systeme allerdings durch die Vielfalt der Trainingsdaten verdeckt und ausgeglichen: Weil nützliche Information im Trainingsdatensatz oft mehrfach und in unterschiedlicher Reihung auftauchen, maskiert dies den Umkehrfluch, wie Berglund und sein Team erklären. Denn die künstliche Intelligenz lernt dann den Zusammenhang unabhängig voneinander in beide Richtungen. Umso wichtiger sei es, die Trainingsdaten entsprechend auszuwählen.
Dennoch sollte nach Ansicht des Forschungsteams nun weiter untersucht werden, inwiefern ChatGPT, Llama und Co auch bei anderen Formen der Umkehrschlüsse Defizite aufweisen. Beispiele wären räumliche Beziehungen wie „Die Tasse steht auf dem Tisch“ und „Der Tisch ist unter der Tasse“, aber auch Rückschlüsse wie: Wenn X gleich Y, dann könnte Nicht-X auch gleich Nicht-Y sein. Denn die Fähigkeit, logische Umkehrschlüsse zu ziehen, sei für viele Anwendungen der KI-Systeme essenziell – beispielsweise in juristischen Fragen oder der Wissenschaft. (Preprint arXiv, doi: 10.48550/arXiv.2309.12288)
Quelle: arXiv











